Benchmarks¶
Also see Custom Benchmarks regarding how to create your own benchmarks or use someone else’s.
Available Groups¶
Like individual benchmarks (see “Available benchmarks” below), benchmarks group
are allowed after the -b option. Use python3 -m pyperformance list_groups
to list groups and their benchmarks.
Available benchmark groups:
all: Group including all benchmarksapps: “High-level” applicative benchmarks (2to3, Chameleon, Tornado HTTP)default: Group of benchmarks run by default by theruncommandmath: Float and integersregex: Collection of regular expression benchmarksserialize: Benchmarks onpickleandjsonmodulesstartup: Collection of microbenchmarks focused on Python interpreter start-up time.template: Templating libraries
Use the python3 -m pyperformance list_groups command to list groups and their
benchmarks.
Available Benchmarks¶
In pyperformance 0.5.5, the following microbenchmarks have been removed because they are too short, not representative of real applications and are too unstable.
call_method_slotscall_method_unknowncall_methodcall_simplepybench
2to3¶
Run the 2to3 tool on the pyperformance/benchmarks/data/2to3/ directory: copy
of the django/core/*.py files of Django 1.1.4, 9 files.
Run the python -m lib2to3 -f all <files> command where python is
sys.executable. So the test does not only mesure the performance of Python
itself, but also the performance of the lib2to3 module which can change
depending on the Python version.
Note
Files are called .py.txt instead of .py to not run PEP 8 checks on
them, and more generally to not modify them.
async_tree¶
Async workload benchmark, which calls asyncio.gather() on a tree (6 levels deep,
6 branches per level) with the leaf nodes simulating some [potentially] async work
(depending on the benchmark variant). Available variants:
async_tree: no actual async work at any leaf node.async_tree_io: all leaf nodes simulate async IO workload (async sleep 50ms).async_tree_memoization: all leaf nodes simulate async IO workload with 90% of the data memoized.async_tree_cpu_io_mixed: half of the leaf nodes simulate CPU-bound workload (math.factorial(500)) and the other half simulate the same workload as theasync_tree_memoizationvariant.
These benchmarks also have an “eager” flavor that uses asyncio eager task factory, if available.
base64¶
Benchmark the base64 module’s encoding and decoding functions. Each
algorithm has _small and _large variants that test both encode and
decode in a single benchmark:
_small: Balanced iterations across 20B, 127B, 3KiB, and 9KB data sizes more likely to show the impact of overhead._large: Large data focus with 100KiB and ~1MiB data sizes likely to demonstrate implementation efficiency.
Available benchmarks:
base64_small,base64_large: Standard Base64 encoding and decodingurlsafe_base64_small: URL-safe Base64 (small only, as URLs shouldn’t contain huge data)base32_small,base32_large: Base32 encoding and decodingbase16_small,base16_large: Base16/hex encoding and decodingascii85_small,ascii85_large: Ascii85 encoding and decoding (includeswrapcol=76code path)base85_small,base85_large: Base85 encoding and decoding
See the base64 module.
btree¶
Benchmark a pure-Python implementation of a B-tree data structure. The tree is created with a relatively large number of nodes (default is 200,000). This attempts to simulate an application that operates on a large number of objects in memory (at least, large compared to other benchmarks currently in this suite). There are two variations of this benchmark: btree records the time to create the B-tree, run gc.collect() and then do some operations on it; the btree_gc_only variant records only the time to run gc.collect() and it skips the operations after creation.
Note that this benchmark does not create any reference cycles that the garbage collector will need to break to free memory.
chameleon¶
Render a template using the chameleon module to create an HTML table of 500
lignes and 10 columns.
See the chameleon.PageTemplate class.
chaos¶
Create chaosgame-like fractals. Command lines options:
--thickness THICKNESS
Thickness (default: 0.25)
--width WIDTH Image width (default: 256)
--height HEIGHT Image height (default: 256)
--iterations ITERATIONS
Number of iterations (default: 5000)
--filename FILENAME.PPM
Output filename of the PPM picture
--rng-seed RNG_SEED Random number generator seed (default: 1234)
When --filename option is used, the timing includes the time to create the
PPM file.
Copyright (C) 2005 Carl Friedrich Bolz

Image generated by bm_chaos (took 3 sec on CPython 3.5) with the command:
python3 pyperformance/benchmarks/bm_chaos.py --worker -l1 -w0 -n1 --filename chaos.ppm --width=512 --height=512 --iterations 50000
crypto_pyaes¶
benchmark a pure-Python implementation of the AES block-cipher in CTR mode
using the pyaes module.
The benchmark is slower on CPython 3 compared to CPython 2.7, because CPython 3
has no more “small int” type (int). The CPython 3 int type now always
has an arbitrary size, as CPython 2.7 long type.
See pyaes: A pure-Python implementation of the AES block cipher algorithm and the common modes of operation (CBC, CFB, CTR, ECB and OFB).
deepcopy¶
Benchmark the Python copy.deepcopy method. The deepcopy method is performed on a nested dictionary and a dataclass.
deltablue¶
DeltaBlue benchmark
Ported for the PyPy project. Contributed by Daniel Lindsley
This implementation of the DeltaBlue benchmark was directly ported from the V8’s source code, which was in turn derived from the Smalltalk implementation by John Maloney and Mario Wolczko. The original Javascript implementation was licensed under the GPL.
It’s been updated in places to be more idiomatic to Python (for loops over
collections, a couple magic methods, OrderedCollection being a list &
things altering those collections changed to the builtin methods) but largely
retains the layout & logic from the original. (Ugh.)
django_template¶
Use the Django template system to build a 150x150-cell HTML table.
Use Context and Template classes of the django.template module.
dulwich_log¶
Iterate on commits of the asyncio Git repository using the Dulwich module.
Use pyperformance/benchmarks/data/asyncio.git/ repository.
Pseudo-code of the benchmark:
repo = dulwich.repo.Repo(repo_path)
head = repo.head()
for entry in repo.get_walker(head):
pass
See the Dulwich project.
docutils¶
Use Docutils to convert Docutils’ documentation to HTML. Representative of building a medium-sized documentation set.
fannkuch¶
The Computer Language Benchmarks Game: http://benchmarksgame.alioth.debian.org/
Contributed by Sokolov Yura, modified by Tupteq.
float¶
Artificial, floating point-heavy benchmark originally used by Factor.
Create 100,000 point objects which compute math.cos(), math.sin() and
math.sqrt()
Changed in version 0.5.5: Use __slots__ on the Point class to focus the benchmark on float rather
than testing performance of class attributes.
genshi¶
Render a template using Genshi (genshi.template module):
genshi_text: Render a HTML template using theNewTextTemplateclassgenshi_xml: Render an XML template using theMarkupTemplateclass
See the Genshi project.
go¶
Artificial intelligence playing the Go board game. Use Zobrist hashing.
hexiom¶
Solver of Hexiom board game (level 25 by default). Command line option:
--level {2,10,20,25,30,36} Hexiom board level (default: 25)
hg_startup¶
Get Mercurial’s help screen.
Measure the performance of the python path/to/hg help command using
pyperf.Runner.bench_command(), where python is sys.executable and
path/to/hg is the Mercurial program installed in a virtual environmnent.
The bench_command() redirects stdout and stderr into /dev/null.
See the Mercurial project.
html5lib¶
Parse the pyperformance/benchmarks/data/w3_tr_html5.html HTML file (132 KB)
using html5lib. The file is the HTML 5 specification, but truncated to
parse the file in less than 1 second (around 250 ms).
On CPython, after 3 warmups, the benchmarks enters a cycle of 5 values: every 5th value is 10% slower. Plot of 1 run of 50 values (the warmup is not rendered):
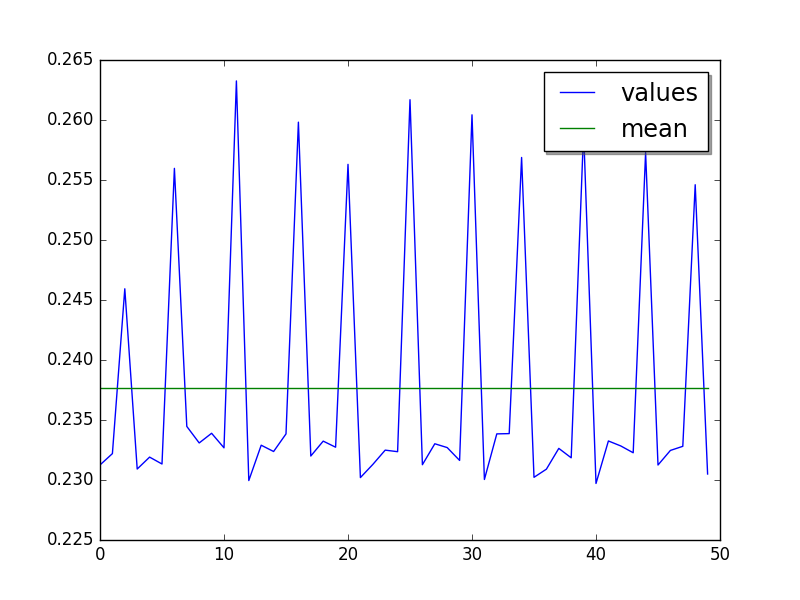
See the html5lib project.
json_dumps, json_loads¶
Benchmark dumps() and loads() functions of the json module.
bm_json_dumps.py command line option:
--cases CASES Comma separated list of cases. Available cases: EMPTY,
SIMPLE, NESTED, HUGE. By default, run all cases.
logging¶
Benchmarks on the logging module:
logging_format: Benchmarklogger.warn(fmt, str)logging_simple: Benchmarklogger.warn(msg)logging_silent: Benchmarklogger.debug(msg)when the log is ignored
Script command line option:
format
silent
simple
See the logging module.
mako¶
Use the Mako template system to build a 150x150-cell HTML table. Includes:
two template inherences
HTML escaping, XML escaping, URL escaping, whitespace trimming
function defitions and calls
forloops
See the Mako project.
mdp¶
Battle with damages and topological sorting of nodes in a graph.
See Topological sorting.
meteor_contest¶
Solver for Meteor Puzzle board.
Meteor Puzzle board: http://benchmarksgame.alioth.debian.org/u32/meteor-description.html#meteor
The Computer Language Benchmarks Game: http://benchmarksgame.alioth.debian.org/
Contributed by Daniel Nanz, 2008-08-21.
nbody¶
N-body benchmark from the Computer Language Benchmarks Game. Microbenchmark on floating point operations.
This is intended to support Unladen Swallow’s perf.py. Accordingly, it has been modified from the Shootout version:
Accept standard Unladen Swallow benchmark options.
Run report_energy()/advance() in a loop.
Reimplement itertools.combinations() to work with older Python versions.
Pulled from: http://benchmarksgame.alioth.debian.org/u64q/program.php?test=nbody&lang=python3&id=1
Contributed by Kevin Carson. Modified by Tupteq, Fredrik Johansson, and Daniel Nanz.
python_startup, python_startup_nosite¶
python_startup: Measure the Python startup time, runpython -c passwherepythonissys.executablepython_startup_nosite: Measure the Python startup time without importing thesitemodule, runpython -S -c passwherepythonissys.executable
Run the benchmark with pyperf.Runner.bench_command().
nqueens¶
Simple, brute-force N-Queens solver.
See Eight queens puzzle.
pathlib¶
Test the performance of operations of the pathlib module of the standard
library.
This benchmark stresses the creation of small objects, globbing, and system calls.
See the documentation of the pathlib module.
pickle¶
pickle benchmarks (serialize):
pickle: use the cPickle module to pickle a variety of datasets.pickle_dict: microbenchmark; use the cPickle module to pickle a lot of dicts.pickle_list: microbenchmark; use the cPickle module to pickle a lot of lists.pickle_pure_python: use the pure-Python pickle module to pickle a variety of datasets.
unpickle benchmarks (deserialize):
unpickle: use the cPickle module to unnpickle a variety of datasets.unpickle_listunpickle_pure_python: use the pure-Python pickle module to unpickle a variety of datasets.
pidigits¶
Calculating 2,000 digits of π. This benchmark stresses big integer arithmetic.
Command line option:
--digits DIGITS Number of computed pi digits (default: 2000)
Adapted from code on: http://benchmarksgame.alioth.debian.org/
pyflate¶
Benchmark of a pure-Python bzip2 decompressor: decompress the
pyperformance/benchmarks/data/interpreter.tar.bz2 file in memory.
Copyright 2006–2007-01-21 Paul Sladen: http://www.paul.sladen.org/projects/compression/
You may use and distribute this code under any DFSG-compatible license (eg. BSD, GNU GPLv2).
Stand-alone pure-Python DEFLATE (gzip) and bzip2 decoder/decompressor. This is probably most useful for research purposes/index building; there is certainly some room for improvement in the Huffman bit-matcher.
With the as-written implementation, there was a known bug in BWT decoding to do with repeated strings. This has been worked around; see ‘bwt_reverse()’. Correct output is produced in all test cases but ideally the problem would be found…
raytrace¶
Simple raytracer.
Command line options:
--width WIDTH Image width (default: 100)
--height HEIGHT Image height (default: 100)
--filename FILENAME.PPM Output filename of the PPM picture
This file contains definitions for a simple raytracer. Copyright Callum and Tony Garnock-Jones, 2008.
This file may be freely redistributed under the MIT license, http://www.opensource.org/licenses/mit-license.php
From https://leastfixedpoint.com/tonyg/kcbbs/lshift_archive/toy-raytracer-in-python-20081029.html

Image generated by the command (took 68.4 sec on CPython 3.5):
python3 pyperformance/benchmarks/bm_raytrace.py --worker --filename=raytrace.ppm -l1 -w0 -n1 -v --width=800 --height=600
regex_compile¶
Stress the performance of Python’s regex compiler, rather than the regex execution speed.
Benchmark how quickly Python’s regex implementation can compile regexes.
We bring in all the regexes used by the other regex benchmarks, capture them by stubbing out the re module, then compile those regexes repeatedly. We muck with the re module’s caching to force it to recompile every regex we give it.
regex_dna¶
regex DNA benchmark using “fasta” to generate the test case.
The Computer Language Benchmarks Game http://benchmarksgame.alioth.debian.org/
regex-dna Python 3 #5 program: contributed by Dominique Wahli 2to3 modified by Justin Peel
fasta Python 3 #3 program: modified by Ian Osgood modified again by Heinrich Acker modified by Justin Peel Modified by Christopher Sean Forgeron
regex_effbot¶
Some of the original benchmarks used to tune mainline Python’s current regex engine.
regex_v8¶
Python port of V8’s regex benchmark.
Automatically generated on 2009-01-30.
This benchmark is generated by loading 50 of the most popular pages on the web and logging all regexp operations performed. Each operation is given a weight that is calculated from an estimate of the popularity of the pages where it occurs and the number of times it is executed while loading each page. Finally the literal letters in the data are encoded using ROT13 in a way that does not affect how the regexps match their input.
Ported to Python for Unladen Swallow. The original JS version can be found at https://github.com/v8/v8/blob/master/benchmarks/regexp.js, r1243.
richards¶
The classic Python Richards benchmark.
Based on a Java version.
Based on original version written in BCPL by Dr Martin Richards in 1981 at Cambridge University Computer Laboratory, England and a C++ version derived from a Smalltalk version written by L Peter Deutsch.
Java version: Copyright (C) 1995 Sun Microsystems, Inc. Translation from C++, Mario Wolczko Outer loop added by Alex Jacoby
scimark¶
scimark_sor: Successive over-relaxation (SOR) benchmarkscimark_sparse_mat_mult: sparse matrix multiplication benchmarkscimark_monte_carlo: benchmark on the Monte Carlo algorithm to compute the area of a discscimark_lu: LU decomposition benchmarkscimark_fft: Fast Fourier transform (FFT) benchmark
spectral_norm¶
MathWorld: “Hundred-Dollar, Hundred-Digit Challenge Problems”, Challenge #3. http://mathworld.wolfram.com/Hundred-DollarHundred-DigitChallengeProblems.html
The Computer Language Benchmarks Game http://benchmarksgame.alioth.debian.org/u64q/spectralnorm-description.html#spectralnorm
Contributed by Sebastien Loisel. Fixed by Isaac Gouy. Sped up by Josh Goldfoot. Dirtily sped up by Simon Descarpentries. Concurrency by Jason Stitt.
sqlalchemy_declarative, sqlalchemy_imperative¶
sqlalchemy_declarative: SQLAlchemy Declarative benchmark using SQLitesqlalchemy_imperative: SQLAlchemy Imperative benchmark using SQLite
See the SQLAlchemy project.
sqlite_synth¶
Benchmark Python aggregate for SQLite.
The goal of the benchmark (written for PyPy) is to test CFFI performance and going back and forth between SQLite and Python a lot. Therefore the queries themselves are really simple.
See the SQLite project and the Python sqlite3 module (stdlib).
sympy¶
Benchmark on the sympy module:
sympy_expand: Benchmarksympy.expand()sympy_integrate: Benchmarksympy.integrate()sympy_str: Benchmarkstr(sympy.expand())sympy_sum: Benchmarksympy.summation()
On CPython, some sympy_sum values are 5%-10% slower:
$ python3 -m pyperf dump sympy_sum.json
Run 1: 1 warmup, 50 values, 1 loop
- warmup 1: 404 ms (+63%)
- value 1: 244 ms
- value 2: 245 ms
- value 3: 258 ms <----
- value 4: 245 ms
- value 5: 245 ms
- value 6: 279 ms (+12%) <----
- value 7: 246 ms
- value 8: 244 ms
- value 9: 245 ms
- value 10: 255 ms <----
- value 11: 245 ms
- value 12: 245 ms
- value 13: 256 ms <----
- value 14: 248 ms
- value 15: 245 ms
- value 16: 245 ms
...
Plot of 1 run of 50 values (the warmup is not rendered):
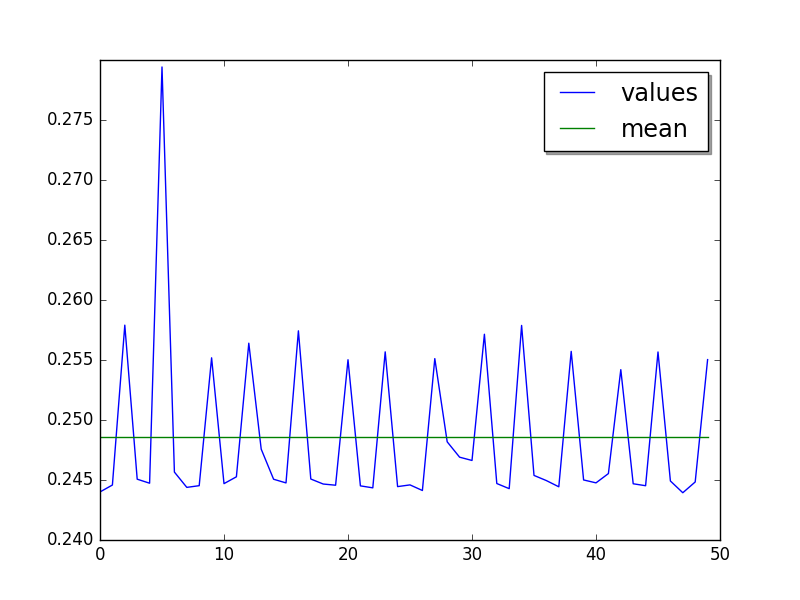
See the sympy project.
telco¶
Telco Benchmark for measuring the performance of decimal calculations:
A call type indicator,
c, is set from the bottom (least significant) bit of the duration (hencecis 0 or 1).A rate,
r, is determined from the call type. Those calls withc=0have a lowr:0.0013; the remainder (‘distance calls’) have a ‘premium’r:0.00894. (The rates are, very roughly, in Euros or dollarates per second.)A price,
p, for the call is then calculated (p=r*n). This is rounded to exactly 2 fractional digits using round-half-even (Banker’s round to nearest).A basic tax,
b, is calculated:b=p*0.0675(6.75%). This is truncated to exactly 2 fractional digits (round-down), and the total basic tax variable is then incremented (sumB=sumB+b).For distance calls: a distance tax,
d, is calculated:d=p*0.0341(3.41%). This is truncated to exactly 2 fractional digits (round-down), and then the total distance tax variable is incremented (sumD=sumD+d).The total price,
t, is calculated (t=p+b, and, if a distance call,t=t+d).The total prices variable is incremented (
sumT=sumT+t).The total price,
t, is converted to a string,s.
The Python benchmark is implemented with the decimal module.
See the Python decimal module (stdlib).
tornado_http¶
Benchmark HTTP server of the tornado module
See the Tornado project.
unpack_sequence¶
Microbenchmark for unpacking lists and tuples.
Pseudo-code:
a, b, c, d, e, f, g, h, i, j = to_unpack
where to_unpack is tuple(range(10)) or list(range(10)).
xml_etree¶
Benchmark the ElementTree API of the xml.etree module:
xml_etree_generate: Create an XML documentxml_etree_iterparse: Benchmarketree.iterparse()xml_etree_parse: Benchmarketree.parse()xml_etree_process: Process an XML document